Repeating Prompts
Someone at work shared an interesting paper from Google called Prompt Repetition Improves Non-Reasoning LLMs. The title pretty much sums up the paper, and the abstract is not much longer!
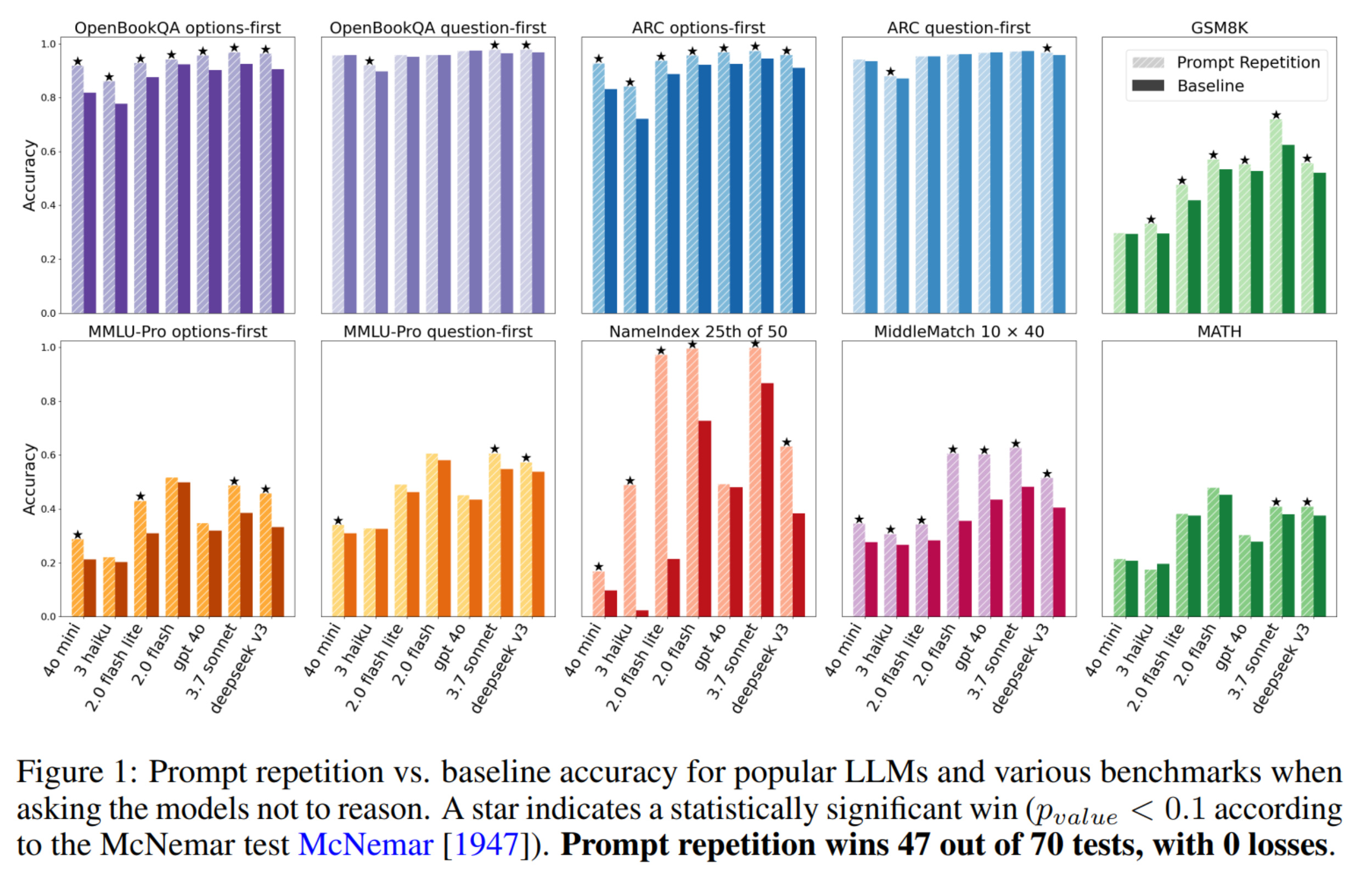
The interesting thing for me is that this kind of trick is still possible despite the amount of work put into improving LLMs. To me, this proves how much room for improvement there still is for current LLMs.
My point is that it shouldn’t be necessary to repeat the prompt or waste tokens on reasoning to get this performance boost. A similar boost could be achieved by removing the causality restriction for prompts. For example, during pre-training the first half of the context could be allowed to attend to any token within that range, while we try and predict the second half.
In fact, that’s pretty much what Katz et al. did in their paper Segment-Based Attention Masking for GPTs. It would be interesting to see if prompt repetition gives an improvement with their models - logically one would expect not.