Making LLMs More Efficient With Search Heads
It has always seemed a little crazy to me that LLMs are expected to re-learn how to do things that can be done trivially on a CPU. For example, it takes billions of FLOPS for an LLM to compute 2 + 2.
While mathematics is definitely something I want to tackle in the future, I’ve started with something simpler that LLMs are expected to learn: how to copy sequences in the input string to the output.
LLMs typically learn to do this through something called an induction head, first identified in work by Anthropic. This is a mechanism in standard transformers that works across two layers.
The first layer copies information from one token into token that follows it, effectively “marking” or “tagging” it with information saying “I just saw this token”.
The second layer looks for one of these tags, and thus knows to attend to the token that came after the previous occurrence of the current token.
Again, this seems like a complex way of searching for strings. To test out this idea, I implemented a specialized “search head” that automatically knows how to perform this task. This is because we do the whole search task in advance on the CPU and pass some extra data through to this head to say where the previous occurrences were. This replaces the standard attention mechanism, allowing the head to attend to the token that comes after its previous occurrence without any K or Q parameters.
As well as reducing the model size, it also allows models to more easily learn how to copy, making them more effective overall.
Of course this type of head cannot learn to do more complex pattern matching like a normal transformer head. But we are augmenting rather than replacing: the idea is to offload the simple work to the search head to free up parameters for the model to learn more complex things.
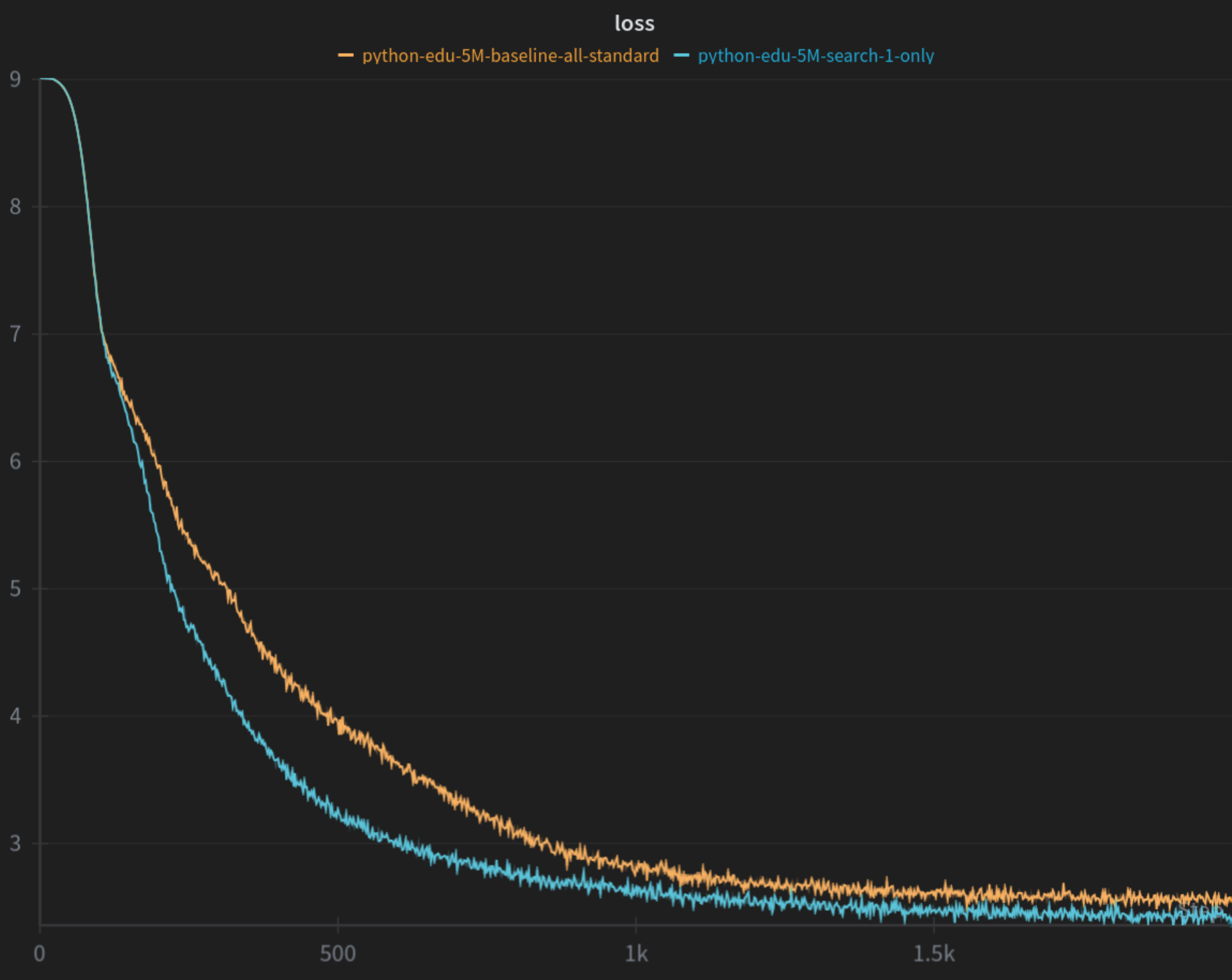
The graph shows the loss for the model containing the specialized head compared to the baseline - the validation loss shows a similar behaviour. I’m in the process of finishing off the experiments and writing up a paper on this idea, so stay tuned…